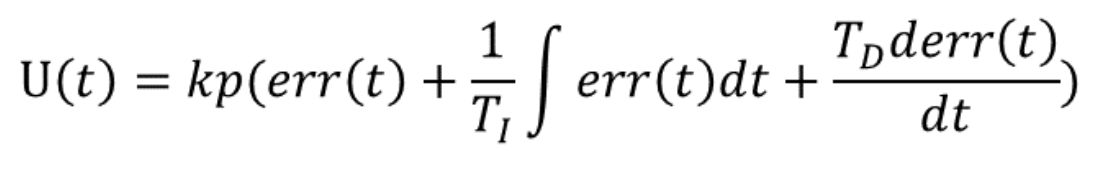标签搜索
.png)

搜索到
8
篇与
的结果
-
 具身智能入门task01 具身智能学习Task1具身智能概述具身智能 = 智能的大脑 + 行动的身体核心挑战Sim-to-Real的不适配性泛化能力 实现通用性数据稀缺问题安全性与伦理问题机器人基础和控制、手眼协调由于学习过控制理论基础课程 不做详细展开PID控制算法P比例参数I 微分参数D 积分参数用于实现姿态等稳定系统的控制 能够有效消除稳态误差 使得系统更为稳定 有效控制很喜欢知乎里网友对PID的这个理解手眼协调教程由于有过手眼标定相关实践 这里只对内容进行梳理复习手眼标定主要用于统一视觉系统与机器人的坐标系当我们希望使用视觉引导机器人去抓取物体时,需要知道三个相对位置关系,即末端执行器与机器人底座之间相对位置关系摄像头与末端执行器之间相对位置关系物体与摄像头之间的相对位置和方向摄像头安装方式分为眼在手上和眼在手外 二者适用场景有些不同 三个相对位置关系也不同手眼标定的数学模型为了标定手眼位置 需要对坐标系进行定义 求出坐标系之间的变换矩阵 进行统一后方便操作这里与相机模型转化类似 不做多余赘述 主要是将不同坐标系之间的刚体变换矩阵求解具身导航基础Habitat-sim环境搭建conda create -n habitat python=3.9 cmake=3.14.0 conda activate habitat因为使用服务器 大部分时间headless使用 故下载无头模式conda install habitat-sim=0.2.5 withbullet headless -c conda-forge -c aihabitat conda install habitat-sim withbullet headless -c conda-forge -c aihabitat执行后 输出结果如图
具身智能入门task01 具身智能学习Task1具身智能概述具身智能 = 智能的大脑 + 行动的身体核心挑战Sim-to-Real的不适配性泛化能力 实现通用性数据稀缺问题安全性与伦理问题机器人基础和控制、手眼协调由于学习过控制理论基础课程 不做详细展开PID控制算法P比例参数I 微分参数D 积分参数用于实现姿态等稳定系统的控制 能够有效消除稳态误差 使得系统更为稳定 有效控制很喜欢知乎里网友对PID的这个理解手眼协调教程由于有过手眼标定相关实践 这里只对内容进行梳理复习手眼标定主要用于统一视觉系统与机器人的坐标系当我们希望使用视觉引导机器人去抓取物体时,需要知道三个相对位置关系,即末端执行器与机器人底座之间相对位置关系摄像头与末端执行器之间相对位置关系物体与摄像头之间的相对位置和方向摄像头安装方式分为眼在手上和眼在手外 二者适用场景有些不同 三个相对位置关系也不同手眼标定的数学模型为了标定手眼位置 需要对坐标系进行定义 求出坐标系之间的变换矩阵 进行统一后方便操作这里与相机模型转化类似 不做多余赘述 主要是将不同坐标系之间的刚体变换矩阵求解具身导航基础Habitat-sim环境搭建conda create -n habitat python=3.9 cmake=3.14.0 conda activate habitat因为使用服务器 大部分时间headless使用 故下载无头模式conda install habitat-sim=0.2.5 withbullet headless -c conda-forge -c aihabitat conda install habitat-sim withbullet headless -c conda-forge -c aihabitat执行后 输出结果如图 -
AutoML autoML学习使用工具auto_ml它主要将机器学习中所有耗时过程自动化,如数据预处理、最佳算法选择、超参数调整等,这样可节约大量时间在建立机器学习模型过程中。进行自动机器学习使用的库为pycaretpycaret——》开源机器学习库不好用从数据准备到模型部署 一行代码实现可以帮助执行端到端机器学习试验 无论是计算缺失值 编码分类数据 实施特征工程 超参数调整还是构建集成模型 都非常方便使用前新建虚拟环境:scikit-learn==0.23.2pycaret跟auto-ts有冲突根据要解决的问题类型,首先需要导入模块。在 PyCaret 的第一个版本中,有 6 个不同的模块可用 ---> 回归、分类、聚类、自然语言处理 (NLP)、异常检测和关联挖掘规则。我们这次要预测新增用户,所以是一个分类问题,我们引入分类模块# import the classification module from pycaret import classification # setup the environment classification_setup = classification.setup( data= data_classification, target='Personal Loan')设置更多自定义参数data_amend = exp_mclf101 = setup( data= data_classification, target='Personal Loan', train_size = 0.80, ignore_features = ["session_id",...], numeric_features =["Age",...], combine_rare_levels= False, rare_level_threshold=0.1, categorical_imputation = 'mode', imputation_type ='simple', feature_interaction = True, feature_ratio= True, interaction_threshold=0.01, session_id=123, fold_shuffle=True, use_gpu=True, fix_imbalance=True, remove_outliers=False,normalize = True, transformation = False, transformation_method='quantile', feature_selection= True, feature_selection_threshold = 0.8, feature_selection_method='boruta', remove_multicollinearity = True, multicollinearity_threshold=0.8 normalize_method = 'robust')在我们使用过程中只需要进行调用函数,函数值接受一个参数,也就是模型缩写这个表格包含了模型缩写字符串最后,我们将对陌生数据进行预测。为此,我们只需要传递将用于预测的数据集的模型。注意的是,确保它与之前设置环境时提供的格式相同。PyCaret 构建了所有步骤的管道,并将预测数据传递到管道中并输出结果。通过拜读群内大佬的数据处理过程 得到以下技巧分组聚合 将x1到x8的数据进行分组聚合 并计算每个分组对于target的均值猜想 有些特征数值比较大 是否使用正则化进行时间序列上的处理 将其转化成月 日 小时 分钟 以及是否为周末 一年中的第几周时间特征实际上并不好用依然使用决策树进行训练这样的训练方法使得分数进行了一定的上升,但依旧存在召回率低的问题
-
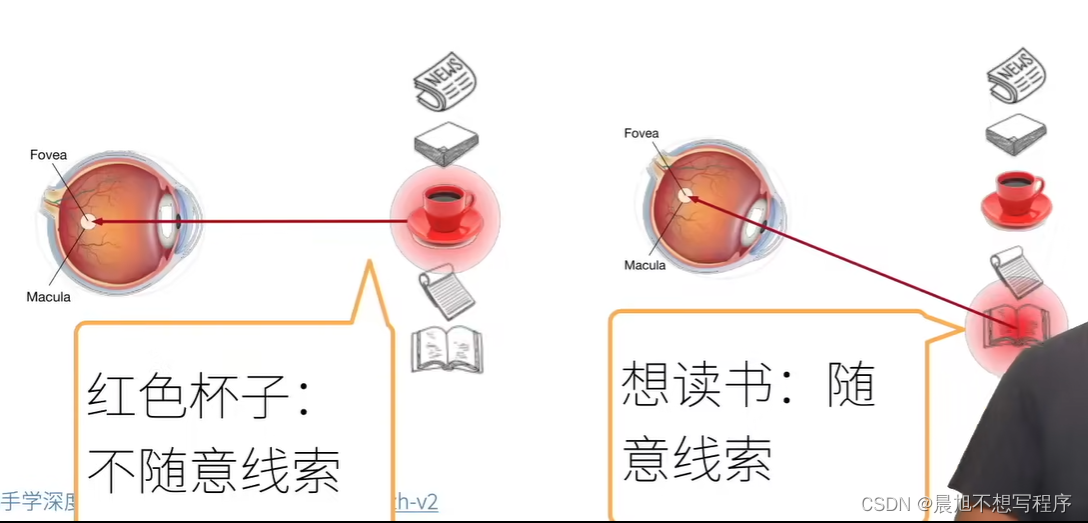
Attention2Transformer 注意力机制什么是注意力首先,心理学上,作为动物,想要在复杂环境下关注到需要关注的事物,机制是根据随意线索和不随意线索选择注意点随意与不随意实际上是遂意与不遂意,也就是是否受控例如这里的在环境中看到红色杯子,是因为杯子颜色鲜艳,会让人第一眼看到,这是不需要遂意的,而想读书带着个人意愿,是遂意的在搜索注意力机制像之前学习过的卷积 全连接 池化层 都是只考虑不随意线索,更倾向于关注有特点的事物注意力机制则显示的考虑随意线索随意线索被称之为查询(query) ——》要求,想法每个输入是一个值(value)和不随意线索(key)的对 ——》 环境,也就是存放一堆事物的场景通过注意力池化层来有偏向性的选择选择某些输入 ——》 根据想法,根据在环境中为事物的不同价值选择观察事物查询,键和值在此之前提出QKV的概念所谓Q即为query,被称为查询,即自主性提示,给定任何查询,注意力机制通过注意力汇聚将选择引导至感官输入,这些感官输入被称为V,即value,每个值都与一个键K,即key匹配,可以想象为非自主性提示。非参注意力汇聚$$ f(x)=\sum_{i=1}^{n}{\frac{K(x-x_{i})}{\sum_{i=1}^{n}{K(x-x_{j})}}}y_{i} $$其中$K()$的作用就是衡量$X$与$X_i$之间关系的一个函数$X$就是所谓的Q,是自主性提示而$X_i$是所谓的K,与V一一对应,是非自主性提示而他们的差值最小二乘,衡量他们的关系,此时二者差距越小,越接近,则此$y_i$所对应的权重就越大,即注意力分配越多,由此就得到了对应的汇聚函数$$ K(u)=\frac{1}{\sqrt{2\pi}}\,\mathrm{Exp}(-\frac{u^{2}}{2}) $$$$ \begin{array}{c}{{f(x)=\sum_{i=1}^{n}\frac{\exp\left(-\frac{1}{2}(x-x_{i})^{2}\right)}{\sum_{j=1}^{n}\exp\left(-\frac{1}{2}(x-x_{j})^{2}\right)}y_{i}}}\\ {{\displaystyle=\sum_{i=1}^{n}\mathrm{softmax}\left(-\frac{1}{2}(x-x_{i})^{2}\right)y_{i}}}\end{array} $$这里实际上就是做了一个softmax操作有参注意力汇聚在此基础上引入可以学习的$w$ ,就实现了有参数的注意力汇聚f(x)= $ \sum _ {i=1}^ {n} $ soft $ \max $ (- $ \frac {1}{2} $ $ ((x-x_ {i})w)^ {2} $注意力评分上文所示高斯核其实就是注意力评分函数,进行运算后得到与键对应的值的概率分布,即注意力权重加性注意力一般来说,当查询和键是不同长度的向量时,可以使用加性注意力作为评分函数k $ \in $ $ R^ {h\times k} $ , $ W_ {q} $ $ \in $ $ R^ {h\times q} $ ,v $ \in $ $ R^ {h} $ a(k,q)= $ v^ {T} $ $ \tanh $ ( $ W_ {k} $ k+ $ W_ {q} $ q)等价于将key与value合并起来后放入到一个隐藏大小为$h$,输出大小为1的单隐藏层MLP缩放点积注意力直接使用点积可以得到计算效率很高的评分函数,但是点积操作需要K与Q拥有相同的长度d,此时如果将a(q, $ k_ {i} $ )= $ \langle $ q, $ k_ {i} $ $\rangle$ /$\sqrt {d} $ 除一个根号d的目的是为了消除长度的影响使用注意力机制的seq2seq之前提到使用两个循环神经网络的编码器解码器结构实现了seq2seq的学习,实现 机器翻译的功能循环神经网络编码器将可变序列转换为固定形状的上下文变量,然后循环神经网络解码器根据生成的词元和上下文变量按词元生成输出序列词元然而不是所有的输入词元 都对 解码某个词元 都有用,在每个解码步骤中仍使用编码相同的上下文变量在此时attention的加入就能改变这一点,科威助力模型Bahdanau,在预测词元时,如果不是所有输入词元都相关,模型将仅对齐输入序列中与当前预测相关的部分,这是通过将上下文变量视为注意力集中的输出来实现的模型图:上图就是一个带此结构的编码解码器模型图中,sources经过embedding后进入RNN形成 编码器,编码器对于每次词的输出作为key和 value(它们是同样的)解码器RNN对上一个词的输出是queryattention的输出与下一个词的词嵌入合并后进入下一次的RNN自注意力机制所谓自注意力就是KVQ都是来自同一个输入所得注:与RNN不同,自注意力机制拥有很高的并行度,复杂度较高位置编码自注意力并没有记录位置信息,所以要用到位置编码,位置编码将位置信息注入到输入里位置编码用于表示绝对或者相对的位置信息,可以是设定好的固定参数,也可以是由学习所得如下就是一种固定好的正余弦函数表示的固定位置编码假设长度为n的序列是n×d的shpe的X,那么使用n×d的shape的位置编码矩阵P来输出X+P作为自编码输入P $ \in $ $ R^ {n\times d} $ : $ p_ {i,2j} $ = $ \sin $ ( $ \frac {i}{10000^ {2j/d}} $ ), $ p_ {i,2j+1} $ = $ \cos $ ( $ \frac {i}{10000^ {2j/d}} $ )如图(比较抽象,花了很久理解)首先横坐标是不同位置索引的数据,不同的函数图像是设定好的,比如可以设定256个col,这个超参数的大小就蕴含了输出向量可以获取的位置信息,这样就保证了不同位置的输出绝对不一样,例如row为0时的输出为[1,0,1,0,1,0,1,0...],不可能存在第二个col输出与此相同的情况,而col的个数代表了蕴含的信息量,越多可获取就越多位置编码与二进制编码类似的效果二进制表示例:使用三位二进制数表示八个数字的信息如图所示,每一个位置,也就是横着拿出来一条,绝对找不到与之相等的一条了,这是不可能的transformertransformer架构transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层第一个子层是多头自注意力汇聚,第二个子层是基于位置的前馈网络收到残差网络的启发,每个子层都采用了残差连接transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层中插入了第三个子层,成为编码器-解码器注意力层,多头注意力多头注意力是一种特殊的使用自注意力的结构是说同一k,v,q,希望抽取不同的信息,例如短距离关系和长距离关系多头注意力使用h个独立的注意力池化,合并各个头输出得到最后的输出有掩码的多头注意力训练解码器对于序列中一个元素输出时,不应该考虑该元素之后的元素,可以通过掩码来实现,也就是计算$X_i$输出时,假装当前序列长度为$i$基于位置的前馈网络也就是图中的逐位前馈网络实际上就是全连接,batch_size,n—》序列长度,dimension由于n的长度不是固定的将输入形状由(b,n,d)变换成(bn,d)作用两个全连接层输出形状由(bn,d)变换回(b,n,d)等价于两层核窗口为1的一维卷积层层归一化self attention加性注意力一般来说,当查询和键是不同长度的向量时,可以使用加性注意力作为评分函数k $ \in $ $ R^ {h\times k} $ , $ W_ {q} $ $ \in $ $ R^ {h\times q} $ ,v $ \in $ $ R^ {h} $ a(k,q)= $ v^ {T} $ $ \tanh $ ( $ W_ {k} $ k+ $ W_ {q} $ q)等价于将key与value合并起来后放入到一个隐藏大小为$h$,输出大小为1的单隐藏层MLP缩放点积注意力直接使用点积可以得到计算效率很高的评分函数,但是点积操作需要K与Q拥有相同的长度d,此时如果将a(q, $ k_ {i} $ )= $ \langle $ q, $ k_ {i} $ $\rangle$ /$\sqrt {d} $ 除一个根号d的目的是为了消除长度的影响现在使用的都是点乘attention
-
Meta Learning 元学习 Meta Learninglearn to learnmeta-X ---》X about X学习如何学习machine Learning是寻找一个函数 定义损失 优化什么是元学习?训练资料作为输入 LOSS取决于训练任务,每个任务中有训练资料与测试资料在元学习中需要考虑多个任务 例如分类过task1的表现后,再看task2的表现最后的loss=$l_1$ + $l_2$得到总体的loss在传统机器学习任务中,我们一般使用训练集的误差作为最终loss而在元学习中我们使用测试集误差作为loss经过训练后我们学到了学习的算法这时候我们使用学习的算法 进行测试将其使用在测试任务,将测试任务的训练资料放进去进行学习学出来一个分类器 将其作用在测试任务的测试集中few shot Learning 与 元学习的关系 :fewshot(目标)经常使用元学习(手段)开始套娃meta L VS ML都有over fitting都要调参 但是meta是调调参的参数 一劳永逸
-
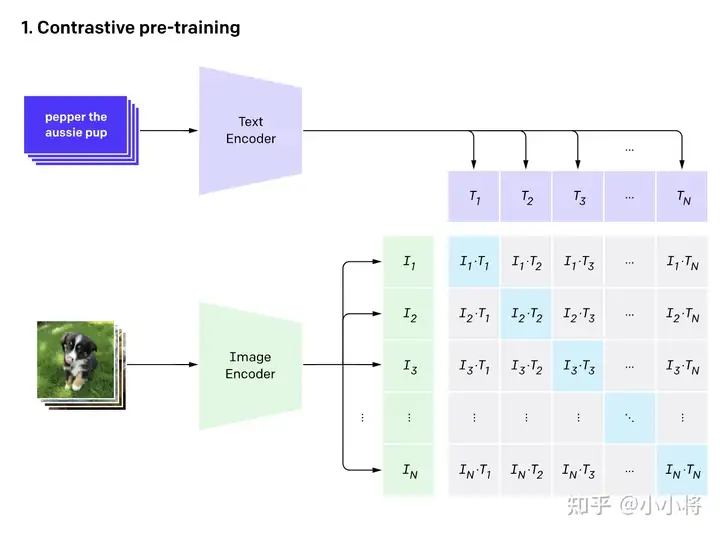
CLIP CLIP论文精读CLIP是什么一个强大的无监督训练模型通过NLP来的监督信号得到迁移学习进行图片与文字的配对实现监督的信号,解决了需要打标签进行训练的限制,增强了模型的泛化能力CLIP结构CLIP的结构包含两个模型Text Encoder和Image Encoder,Text Encoder用于提取文本特征,Image Encoder用来提取图像特征CLIP训练CLIP的训练数据是图像-文本对,如图上方是对小狗的描述,而下方是这张图片,通过对文本的特征提取与对图像的特征提取进行对比学习,对于N个图像文字对,预测出$N^2$个相似度,这里的相似度直接结算文本特征和图像特征的余弦相似性,实际上真实对应的相似对是位于对角线上的元素,我们的目的就是最大化对角线上的元素而减小非对角线上的元素实现zero-shot分类首先先将分类标签扩充成句子后输入到 TextEncoder中,而进行分类时的标签并不需要是训时存在的标签 ,你完全可以新加一个背带裤的标签进行分类,训练与推理时都没有标签的限制,属实是将视觉与文字的语义相关性真正学习到了。使用clip可以辅助实现风格迁移,AI换脸换衣,图像检测 分割,视频检索论文部分采用有限制性的监督信号会限制模型的泛化性这一点毋庸置疑 ,要识别新的物体类别时候就有了困难所以CLIP的想法就是由语言生成监督信号 经过测试,CLIP在ImageNet上可以跟专门为了ImageNet训练出来的resnet50打成平手 达到了非常好的效果并且可以随着两个模型性能继续增长后可以达到不断的进步从文本出来的弱监督信号不实用,是因为数据量不足够与算力消耗大方法上实际上都差不多,但是数据量规模是其想成长的必要因素像VirTex,ICMLM,ConVIRT这些工作都进行过类似的尝试,但是都是只训练了几天的规模,并不足以达到很好的效果于是openAI团队为了证明这一点 收集了超级大规模的数据想要达到比较好的效果再加上大模型的加持,可以达到非常不错的效果,这就是CLIP(Contrastive Language-Image Pre-training)对于模型选择,作者团队也尝试了多种的尝试,发现CLIP的效果跟模型规模是有正相关的最终得到的效果是,CLIP在30多个数据集上基本都能与精心设计的模型打成平手甚至胜利,并且会有更好的泛化性使用CLIP的好处有很多,其中之一就是CLIP不需要再对数据进行标注,只需要获得文本—图像对就可以,像在社交平台上获得的图片跟他发布时的TAG就是一个很好的途径,这种数据往往比标注的数据更容易获取,另外,通过文本—图像对的这种数据集训练,使得其拥有了多模态的效果 在预训练过程中,作者团队采用了对比学习的方法,之所以使用这样的方法而不是用GPT就是因为语言的多样性导致对应关系有很多(例如一张图片可以从多个角度描述),所以我们只需要让图片与文本配对即可,通过这样就能达到很高的效率代码的实现在实现方面,通过论文所给伪代码# image_encoder - ResNet or Vision Transformer # text_encoder - CBOW or Text Transformer # I[n, h, w, c] - minibatch of aligned images # T[n, l] - minibatch of aligned texts # W_i[d_i, d_e] - learned proj of image to embed # W_t[d_t, d_e] - learned proj of text to embed # t - learned temperature parameter # 分别提取图像特征和文本特征 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] # 在得到特征时一般会尝试归一化 在归一化前,还涉及到了投射层,即np.dot(I_f, W_i),主要用来学习如何从单模态投射到多模态 # 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化 I_e = l2_normalize(np.dot(I_f, W_i), axis=1) T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 计算缩放的余弦相似度:[n, n] logits = np.dot(I_e, T_e.T) * np.exp(t) # 对称的对比学习损失:等价于N个类别的cross_entropy_loss labels = np.arange(n) # 对角线元素的labels loss_i = cross_entropy_loss(logits, labels, axis=0) loss_t = cross_entropy_loss(logits, labels, axis=1) loss = (loss_i + loss_t)/2步骤解释提取图像特征和文本特征:使用预训练的 image_encoder 和 text_encoder 分别提取图像 I 和文本 T 的特征,得到形状为 [n, d_i] 和 [n, d_t] 的特征向量。线性投射和归一化:对两个特征进行线性投射,分别用矩阵 W_i 和 W_t,得到相同维度的特征向量 I_e 和 T_e。对投射后的特征进行 l2 归一化,保证它们具有单位长度。计算缩放的余弦相似度:通过计算余弦相似度矩阵,得到形状为 [n, n] 的 logits 矩阵。这一步涉及将图像特征和文本特征进行相似度计算,并使用温度参数 t 进行缩放。对称的对比学习损失:创建标签 labels,其中包含了元素从 0 到 n-1。计算两个方向上的交叉熵损失:loss_i 是以图像为查询,文本为正样本的损失;loss_t 是以文本为查询,图像为正样本的损失。最终的损失是两个方向上损失的平均值,即 (loss_i + loss_t) / 2。这个损失函数的设计旨在通过最大化正样本之间的相似度、最小化负样本之间的相似度,来学习图像和文本之间的语义对应关系。这种对称性的设计可以帮助提升模型的泛化能力,使得图像和文本之间的表示更加一致和可靠。