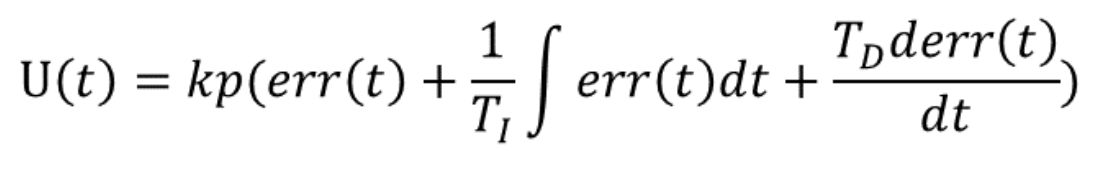标签搜索
.png)

搜索到
18
篇与
的结果
-
 将服务器设置为密钥登陆 将服务器更改为密钥登录(SSH Key Authentication)是提高服务器安全性的最佳实践之一。它不仅比密码更安全(防止暴力破解),而且登录也更方便。第一步:在本地机器生成密钥对如果你还没有密钥对,请在你的本地电脑(Windows PowerShell、Mac 或 Linux 终端)上运行以下命令:ssh-keygen -t rsa -b 4096提示: 系统会询问保存路径(默认即可)和密码短语(Passphrase)。密码短语是给私钥加的二次锁,建议设置。执行完成后,你会得到两个文件:id_rsa(私钥:绝对不能泄露给任何人!)id_rsa.pub(公钥:要上传到服务器的文件)第二步:将公钥上传到服务器你需要将本地生成的 id_rsa.pub 内容复制到服务器上的 ~/.ssh/authorized_keys 文件中。方法 A:使用 ssh-copy-id(最推荐,最简单)在本地终端输入:ssh-copy-id 用户名@服务器IP输入一次服务器密码后,公钥会自动安装完成。方法 B:手动复制(如果方法 A 不可用)在本地查看并复制公钥内容:cat ~/.ssh/id_rsa.pub登录服务器,执行:mkdir -p ~/.ssh chmod 700 ~/.ssh echo "你的公钥字符串" >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys第三步:测试密钥登录在进行后续高风险操作前,请先验证密钥是否生效:ssh 用户名@服务器IP如果无需输入服务器密码(或只需输入你设置的私钥密码短语)即可登录,说明设置成功。第四步:禁用密码登录(安全加固)确认密钥登录成功后,你可以关闭密码登录以彻底杜绝暴力破解。编辑 SSH 配置文件:sudo nano /etc/ssh/sshd_config 修改以下关键参数(如果前面有 # 号请去掉): Plaintext PubkeyAuthentication yes # 允许公钥登录 PasswordAuthentication no # 禁止密码登录 ChallengeResponseAuthentication no UsePAM no # 如果你不需要通过 PAM 认证 重启 SSH 服务: sudo systemctl restart ssh
将服务器设置为密钥登陆 将服务器更改为密钥登录(SSH Key Authentication)是提高服务器安全性的最佳实践之一。它不仅比密码更安全(防止暴力破解),而且登录也更方便。第一步:在本地机器生成密钥对如果你还没有密钥对,请在你的本地电脑(Windows PowerShell、Mac 或 Linux 终端)上运行以下命令:ssh-keygen -t rsa -b 4096提示: 系统会询问保存路径(默认即可)和密码短语(Passphrase)。密码短语是给私钥加的二次锁,建议设置。执行完成后,你会得到两个文件:id_rsa(私钥:绝对不能泄露给任何人!)id_rsa.pub(公钥:要上传到服务器的文件)第二步:将公钥上传到服务器你需要将本地生成的 id_rsa.pub 内容复制到服务器上的 ~/.ssh/authorized_keys 文件中。方法 A:使用 ssh-copy-id(最推荐,最简单)在本地终端输入:ssh-copy-id 用户名@服务器IP输入一次服务器密码后,公钥会自动安装完成。方法 B:手动复制(如果方法 A 不可用)在本地查看并复制公钥内容:cat ~/.ssh/id_rsa.pub登录服务器,执行:mkdir -p ~/.ssh chmod 700 ~/.ssh echo "你的公钥字符串" >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys第三步:测试密钥登录在进行后续高风险操作前,请先验证密钥是否生效:ssh 用户名@服务器IP如果无需输入服务器密码(或只需输入你设置的私钥密码短语)即可登录,说明设置成功。第四步:禁用密码登录(安全加固)确认密钥登录成功后,你可以关闭密码登录以彻底杜绝暴力破解。编辑 SSH 配置文件:sudo nano /etc/ssh/sshd_config 修改以下关键参数(如果前面有 # 号请去掉): Plaintext PubkeyAuthentication yes # 允许公钥登录 PasswordAuthentication no # 禁止密码登录 ChallengeResponseAuthentication no UsePAM no # 如果你不需要通过 PAM 认证 重启 SSH 服务: sudo systemctl restart ssh -
具身智能入门task01 具身智能学习Task1具身智能概述具身智能 = 智能的大脑 + 行动的身体核心挑战Sim-to-Real的不适配性泛化能力 实现通用性数据稀缺问题安全性与伦理问题机器人基础和控制、手眼协调由于学习过控制理论基础课程 不做详细展开PID控制算法P比例参数I 微分参数D 积分参数用于实现姿态等稳定系统的控制 能够有效消除稳态误差 使得系统更为稳定 有效控制很喜欢知乎里网友对PID的这个理解手眼协调教程由于有过手眼标定相关实践 这里只对内容进行梳理复习手眼标定主要用于统一视觉系统与机器人的坐标系当我们希望使用视觉引导机器人去抓取物体时,需要知道三个相对位置关系,即末端执行器与机器人底座之间相对位置关系摄像头与末端执行器之间相对位置关系物体与摄像头之间的相对位置和方向摄像头安装方式分为眼在手上和眼在手外 二者适用场景有些不同 三个相对位置关系也不同手眼标定的数学模型为了标定手眼位置 需要对坐标系进行定义 求出坐标系之间的变换矩阵 进行统一后方便操作这里与相机模型转化类似 不做多余赘述 主要是将不同坐标系之间的刚体变换矩阵求解具身导航基础Habitat-sim环境搭建conda create -n habitat python=3.9 cmake=3.14.0 conda activate habitat因为使用服务器 大部分时间headless使用 故下载无头模式conda install habitat-sim=0.2.5 withbullet headless -c conda-forge -c aihabitat conda install habitat-sim withbullet headless -c conda-forge -c aihabitat执行后 输出结果如图
-
-
MySQL MySQL功能实现对于大量数据的储存增删改查速度更快对于程序的对接比较友好数据库的本质也是文件数据库:用来管理数据表的数据表:用来储存具体的数据的字段:是用来储存一类信息的一列记录:是用来描述一个人或事物的详细信息的一行主键:用来表示唯一一行记录的特殊字段(数值存在且唯一)关系型数据库:表和表之间可以发生关联的数据库基础语法DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的数据进行增删改DQL: 数据查询语言,用来查询数据库中表的记录DCL: 数据控制语言,用来创建数据库用户、控制数据库的控制权限DDL(数据定义语言)数据库操作#查询所有数据库 SHOW DATABASES; #查询当前数据库 SELECT DATABASE(); #创建数据库 CREATE DATABASE [ IF NOT EXISTS ] 数据库名 [ DEFAULT CHARSET 字符集] [COLLATE 排序规则 ]; #删除数据库 DROP DATABASE [ IF EXISTS ] 数据库名; #使用数据库 USE 数据库名;注意:推荐字符集使用utf8mb4字符集表操作#查询当前数据库所有表: SHOW TABLES; #查询表结构: #DESC 表名; #查询指定表的建表语句: SHOW CREATE TABLE 表名; #创建表: CREATE TABLE 表名( 字段1 字段1类型 [COMMENT 字段1注释], 字段2 字段2类型 [COMMENT 字段2注释], 字段3 字段3类型 [COMMENT 字段3注释], ... 字段n 字段n类型 [COMMENT 字段n注释] )[ COMMENT 表注释 ]; #添加字段: ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束]; #修改数据类型: ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度); #修改字段名和字段类型: ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束]; #删除字段: ALTER TABLE 表名 DROP 字段名; #修改表名: ALTER TABLE 表名 RENAME TO 新表名 #删除表: DROP TABLE [IF EXISTS] 表名; #删除表,并重新创建该表: TRUNCATE TABLE 表名;DML(数据操作语言)#向指定字段添加数据: INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...); #向全部字段添加数据: INSERT INTO 表名 VALUES (值1, 值2, ...); #批量添加数据: INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...); INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...); #修改数据: UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [ WHERE 条件 ]; #删除数据: DELETE FROM 表名 [ WHERE 条件 ];DQL(数据查询语言)语法SELECT 字段列表 FROM 表名字段 WHERE 条件列表 GROUP BY 分组字段列表 HAVING 分组后的条件列表 ORDER BY 排序字段列表 LIMIT 分页参数#查询多个字段: SELECT 字段1, 字段2, 字段3, ... FROM 表名; SELECT * FROM 表名; #设置别名: SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名; SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名; #去除重复记录: SELECT DISTINCT 字段列表 FROM 表名;特殊查询#条件查询 SELECT 字段列表 FROM 表名 WHERE 条件列表; #聚合查询 SELECT 聚合函数(字段列表) FROM 表名; #分组查询 SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ]; #排序查询 SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2; #分页查询 SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;聚合函数<br/>函数功能count统计数量max最大值min最小值avg平均值sum求和排序方式ASC: 升序(默认)DESC: 降序注意事项起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10DQL执行顺序FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMITDCL(数据控制语言)#查询用户: USE mysql; SELECT * FROM user; #创建用户: CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码'; #修改用户密码: ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'; #删除用户: DROP USER '用户名'@'主机名'; #查询权限: SHOW GRANTS FOR '用户名'@'主机名'; #授予权限: GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; #撤销权限: REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';常用权限:权限说明ALL, ALL PRIVILEGES所有权限SELECT查询数据INSERT插入数据UPDATE修改数据DELETE删除数据ALTER修改表DROP删除数据库/表/视图CREATE创建数据库/表
-
数据解析 数据解析在最近学习中我们学习了两种解析方法,分别是正则表达式的re解析与BeautifulSoup解析器的使用一、正则表达式正则表达式是用来避免重复工作,处理有规律信息的一个有力工具import re text = "Hi, I am Shirley Hilton. I am his wife." m = re.findall(r"hi", text) if m: print (m) else: print ('not match')这是一个小实验,通过它来看,我们不难看出这是在通过某种方法寻找"Hi, I am Shirley Hilton. I am his wife."这段话中的"hi"通过这个我们发现会有两个结果,都是hi,分别来自于Shirly与his俩单词,由此我们看出,正则表达式是严格的,区分大小写的,Hi并不满足要求。当然,不仅仅有这样的查找,也可以仅仅找部分的,比如只匹配“Hi”,在这段话中只想要计数一次,那么我们可以采用"\bHi\b"的查找对象,这样就能仅仅匹配单独的Hi啦。“\b”在正则表达式中表示单词的开头或结尾,空格、标点、换行都算是单词的分割。而“\b”自身又不会匹配任何字符,它代表的只是一个位置。所以单词前后的空格标点之类不会出现在结果里。然后[]符号的作用也很大,它的作用是表示满足括号中任一字符,例如我们想要Hi也想要hi,就可以[Hh]ir接下来继续解释这个小试验中的内容,在语句传参时的r的含义,为什么要加r?<br/>r,是raw的意思,它表示对字符串不进行转义。例如:>>> print ("\bhi") hi >>> print (r"\bhi") \bhirere是python里的正则表达式模块。findall是其中一个方法,用来按照提供的正则表达式,去匹配文本中的所有符合条件的字符串。返回结果是一个包含所有匹配的list。特殊字符这里介绍.除换行符以外的任意字符\S不是空白符的任意字符*表示前面的字符可以重复任意多次(包括0次)+表示前面的字符可以重复任意多次(不包括0次){}表示指定长度[][]内任意字符\w匹配字母或数字或下划线或汉字 \d匹配数字\s匹配空白符^ 匹配字符串的开始$匹配字符串的结束?重复零次或一次(懒惰匹配){n,}重复n次或更多次{n,m}重复n到m次很容易猜想到,如\s\S这样大小写的区分就是正反的区别,由此推出各个对应的相反,此外,[^]内通过加^就代表除此符号外任意字符.*贪婪匹配/*?懒惰匹配二、BeautifulSoup解析器[1]简介Beautiful Soup是Python的一个库,能够从网页抓取数据提供了一些函数用来处理数据,用很少的代码就能够写出来一个完整的程序。[2]特点Beautiful Soup能够自动的将文档转换为utf-8编码格式,能够更为方便的进行使用使用[1]创建对象要想创建一个Beautiful Soup对象,首先要导入库bs4,lxml,requests。这里使用一个实例html = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html,'lxml') #创建 beautifulsoup 对象同时也可以使用HTML文件直接创建对象soup1 = BeautifulSoup(open('index.html')) Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:TagNavigableStringBeautifulSoupComment1>TagTag就是 HTML 中的一个个标签通过这种方法就可以直接访问标签print (soup.title) print (soup.head) print (soup.a) print (soup.p) print (type(soup.a))Tag有两个重要的属性,name与attrs并且可以对这些属性和内容进行修改2>NavigableString得到了标签的内容用 .string 即可获取标签内部的文字例如print(soup.a.string)3>BeautifulSoupBeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称:4>Comment[2]遍历文档树tag 的 .contents 属性可以将tag的子节点以列表的方式输出.children属性生成的是一个列表生成器对象,可以通过遍历获得其中的内容.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似,要获取其中的内容,我们需要对其进行遍历还有许多关联选择方法[3]CSS选择器CSS的使用只需要调用select方法结合CSS选择器语法就可以实现元素定位格式:soup.select()1>id选择器每段节点都有专属的id,通过id就可以匹配相应的节点,使用#加id就可以实现定位2>类选择器类选择器用.来定位元素例如The Dormouse's story中的title就是类名3>标签选择器直接使用标签来定位即可例如p在定位时可以多种定位方法混合使用,达到更为理想的效果。[4]CSS高级用法1>嵌套选择因为其仍旧是一个tag对象,所以可以使用嵌套选择2>属性获取使用attrs属性3>文本获取使用string与strings获取文本信息[5]方法选择器1>find_all()方法soup传入整个HTML文档然后进行全文搜索find_all(name,attrs,recursive,text,**kwargs)name参数就是查找名字为name的节点,返回tag对象,这个传入的参数可以是字符串,可以是列表,正则,还可以是True(以此为参数可以获取所有的标签)attrs参数是查询含有接受的属性值的标签,参数形式为字典类型例如{id:'link1'}kwargs参数是接收常用的属性参数的,如id和class,参数形式是变量赋值的形式,例如(id='link1')<br/>class 是关键字,使用时应该加下划线即class_=……text参数是通过查询含有接受的文本的标签来查找的,参数形式是字符串limit参数是用于限制返回结果的数量的参数,参数形式是整数,顾名思义recursive参数是决定是否获取子孙节点的参数,参数形式是布尔值,默认是True2>find方法返回值是第一个符合条件的元素,除limit参数不存在外,其余参数都与find_all方法一致