标签搜索
.png)

搜索到
3
篇与
的结果
-
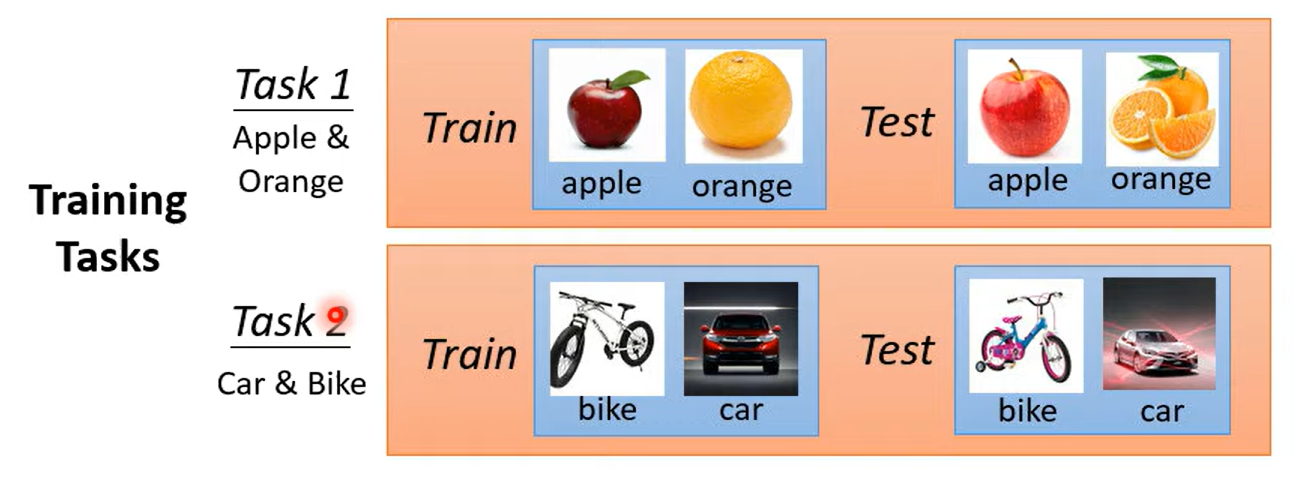
 Meta Learning 元学习 Meta Learninglearn to learnmeta-X ---》X about X学习如何学习machine Learning是寻找一个函数 定义损失 优化什么是元学习?训练资料作为输入 LOSS取决于训练任务,每个任务中有训练资料与测试资料在元学习中需要考虑多个任务 例如分类过task1的表现后,再看task2的表现最后的loss=$l_1$ + $l_2$得到总体的loss在传统机器学习任务中,我们一般使用训练集的误差作为最终loss而在元学习中我们使用测试集误差作为loss经过训练后我们学到了学习的算法这时候我们使用学习的算法 进行测试将其使用在测试任务,将测试任务的训练资料放进去进行学习学出来一个分类器 将其作用在测试任务的测试集中few shot Learning 与 元学习的关系 :fewshot(目标)经常使用元学习(手段)开始套娃meta L VS ML都有over fitting都要调参 但是meta是调调参的参数 一劳永逸
Meta Learning 元学习 Meta Learninglearn to learnmeta-X ---》X about X学习如何学习machine Learning是寻找一个函数 定义损失 优化什么是元学习?训练资料作为输入 LOSS取决于训练任务,每个任务中有训练资料与测试资料在元学习中需要考虑多个任务 例如分类过task1的表现后,再看task2的表现最后的loss=$l_1$ + $l_2$得到总体的loss在传统机器学习任务中,我们一般使用训练集的误差作为最终loss而在元学习中我们使用测试集误差作为loss经过训练后我们学到了学习的算法这时候我们使用学习的算法 进行测试将其使用在测试任务,将测试任务的训练资料放进去进行学习学出来一个分类器 将其作用在测试任务的测试集中few shot Learning 与 元学习的关系 :fewshot(目标)经常使用元学习(手段)开始套娃meta L VS ML都有over fitting都要调参 但是meta是调调参的参数 一劳永逸 -
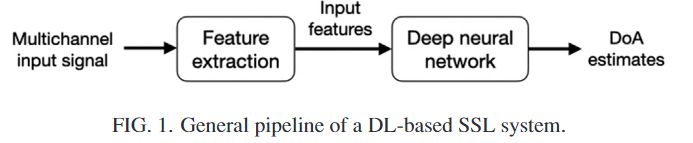
SSL综述 SSL(SoundSourceLocation)声源定位,是是我们任务一的主要研究主题题我们通过这一文献A survey of sound source localization with deep learning methods中的简要介绍了解到声源定位大多数场景下的主要任务其实是DOA,也就是direction of arrival关注于方位角与仰角的研究,并不注重于距离的研究传统的SSL方法是基于信号/信道模型和信号处理(SP)技术。尽管多年来它们在该领域的显着进步,但在可能存在噪声、混响和几个同时发射声源的困难但常见的场景中,它们表现不佳。在近几年,深度学习成果不断涌出,很多研究都证明DL方法在一些SSL场景下比传统方法更优秀,尽管如此,在过往对于SSL问题解决的综述中只有很少提及到DL方法,本文就是为综述DL在SSL方向的应用而作,总结近几年间使用的DL on SSL方法针对DL SSL方法,我们一般使用麦克风阵列获得的多通道输入信号进行特征提取后作为输入特征输入神经网络 最后得出DOA的预测在最新的一些研究中,特征提取模块往往被省略掉,多通道信号直接输入DNN麦克风阵列中,麦克风之间的距离相比于麦克风到声源的距离要近,虽然从信号波形上来看他们差不多但是在延迟与振幅方面都有或多或少的差距,这些差距主要来源于源到不同麦克风的不同传播路径,对于直接路径和在室内环境中组成混响的大量反射麦克风信号通常使用时频(TF)表示,使用短时傅里叶变换SSL的一大难点就是不同源头的声音在传播时,在时间轴上有了重合,其实就是同时有多个音源进行发声,如何准确分离他们也是一件很重要的任务,出现反射现象与嘈杂环境的时候,声源之间的位置关系较为复杂传统难点:多音源同时发声反射噪声传统方法通常对于情况进行假设后进行建模,在真实世界中并不都能起到作用而深度学习方法能够对于真实的数据进行适应,当然这也造成了DNN缺点:DNN方法在一般场景下的主要缺点就是不通用高效(受限于训练成本与所需数据量)深度学习的缺点就是如果给定配置发生变化 得出的结果也不满意方法分类TDoA当麦克风阵列形状已知时,DOA估计可以通过估计麦克风之间源的到达时间差(TDoA)来决定GCC-PHAT具有相位变换的广义互相关(CC)方法(GCC-PHAT)是处理2麦克风阵列时最常用的方法之一,它被是两个麦克风信号之间的交叉功率谱(CPS)的加权版本的逆傅里叶变换广义互相关函数表示的就是同一声源在时延 s 下两个麦克风信号之间的相关性。$X_i(f)$是麦克风信号经过傅里叶变换后的频域表示使用复共轭(*)是一种特殊的处理办法,只有这样才能保留交叉功率谱的相位差接下来我们进行PHAT加权 其形式就是公式主体部分,使用获得的交叉功率谱除以幅值通过寻找使得广义互相关函数最大的时延参数,即两个麦克风获取的信号相似度最高时,达到最好估计时间差的效果,这样能够获得最准确的时间差目前GCC方法已经扩展到了两个以上麦克风的情况这种方法本身具有一定的抗噪声与抗混响能力,但是在信噪比降低、混响增强时,该算法性能急剧下降SRP-PHATTDOA这种方法没有用到阵列整体的优势,缺乏稳健性。而基于可控响应功率(SRP)的波束形成技术,具有较强的稳健性、抗噪性,以及具有一定的空域滤波性能,能够提高信号的信噪比,增加探测距离。在确定声源位置时,一般采用最优化算法,最小二乘法容易陷入局部极值点,而基于自然选择法则的遗传算法(GA)模拟生物进化过程,具有并行计算的特点,是一种全局搜索算法,能够得到全局最优解。将基于可控响应功率的波束形成技术和遗传法算法应用于枪声定位系统中,并通过实际的试验数据对此方法进行了验证,从结果来看具有较高的精度。基于相位变换加权的可控响应功率的声源定位算法这种方法具有较强的鲁棒性 但是在低信噪比的环境下定位性能较差,计算量较大,不经常使用SRP-PHAT对阵型没有特定要求,因此也适用于分布式阵列,事实上很多基于分布式阵列的定位系统采用了该算法。这种方法就是在空间中一点做出所有麦克风对信号的GCCPHAT和,在整个声源空间中寻找使得SRP值最大的点即为声源位置估计MUSIC基于高分辨率谱估计的声源定位方法:通过分析每个元素信号之间的相关性,构造 出一个拟合矩阵,从而确定声源位置。MUSIC算法首先通过将阵列接收到的信号进行空间谱估计,得到信号在不同方向到达时的空间谱。然后,通过对这些空间谱进行分解,可以找到信号所在的方向。将阵列输出数据的协方差矩阵进行特征分解,从而得到与信号分量相对应的信号子空间和与信号分量相正交的噪声子空间。 利用这两个子空间的正交性,构造一个空间谱函数,该函数在信号源所在方向处具有 尖峰。通过搜索空间谱函数的峰值,可以得到信号源的方向估计。1、构建信号接收矩阵,将阵列接收到的信号按照时间在矩阵中排列,每一列对应一个传感器接收到的信号。2、利用接收信号矩阵计算协方差矩阵,并对其进行特征值分解,得到信号的空间谱。空间谱表示了信号在不同方向到达时的能量分布。协方差矩阵描述了各个传感器接收到信号之间的相关性和变化。对协方差矩阵进行特征值分解。特征值分解是一种将矩阵分解为特征向量和特征值的操作。在这里,我们得到的特征向量描述了信号在各个方向上的空间谱,而特征值表示了信号在这些方向上的能量。为什么通过特征分解能够得到各个方向上的空间谱,并且能够构成信号子空间与噪声子空间,3、利用空间谱进行DOA估计,通过对空间谱进行分析,可以找到信号的主要方向。在MUSIC算法中,通过选取空间谱中的极值点(通常是最小的N个特征值对应的特征向量),可以确定信号的方向到达。https://zhuanlan.zhihu.com/p/613304918
-
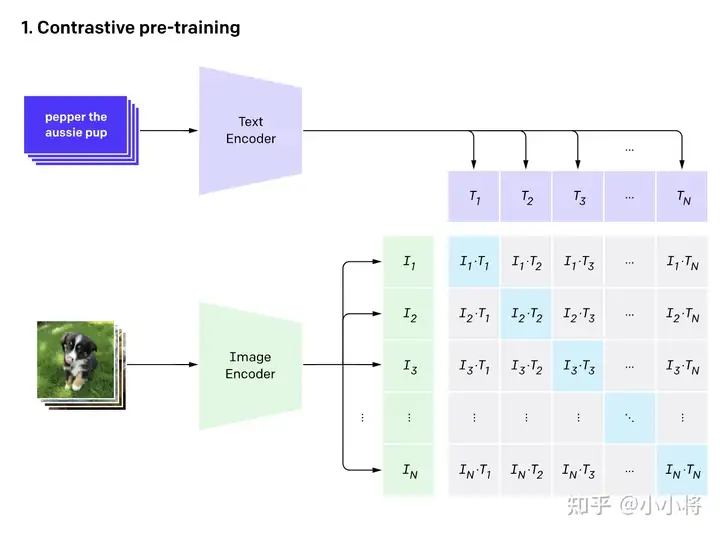
CLIP CLIP论文精读CLIP是什么一个强大的无监督训练模型通过NLP来的监督信号得到迁移学习进行图片与文字的配对实现监督的信号,解决了需要打标签进行训练的限制,增强了模型的泛化能力CLIP结构CLIP的结构包含两个模型Text Encoder和Image Encoder,Text Encoder用于提取文本特征,Image Encoder用来提取图像特征CLIP训练CLIP的训练数据是图像-文本对,如图上方是对小狗的描述,而下方是这张图片,通过对文本的特征提取与对图像的特征提取进行对比学习,对于N个图像文字对,预测出$N^2$个相似度,这里的相似度直接结算文本特征和图像特征的余弦相似性,实际上真实对应的相似对是位于对角线上的元素,我们的目的就是最大化对角线上的元素而减小非对角线上的元素实现zero-shot分类首先先将分类标签扩充成句子后输入到 TextEncoder中,而进行分类时的标签并不需要是训时存在的标签 ,你完全可以新加一个背带裤的标签进行分类,训练与推理时都没有标签的限制,属实是将视觉与文字的语义相关性真正学习到了。使用clip可以辅助实现风格迁移,AI换脸换衣,图像检测 分割,视频检索论文部分采用有限制性的监督信号会限制模型的泛化性这一点毋庸置疑 ,要识别新的物体类别时候就有了困难所以CLIP的想法就是由语言生成监督信号 经过测试,CLIP在ImageNet上可以跟专门为了ImageNet训练出来的resnet50打成平手 达到了非常好的效果并且可以随着两个模型性能继续增长后可以达到不断的进步从文本出来的弱监督信号不实用,是因为数据量不足够与算力消耗大方法上实际上都差不多,但是数据量规模是其想成长的必要因素像VirTex,ICMLM,ConVIRT这些工作都进行过类似的尝试,但是都是只训练了几天的规模,并不足以达到很好的效果于是openAI团队为了证明这一点 收集了超级大规模的数据想要达到比较好的效果再加上大模型的加持,可以达到非常不错的效果,这就是CLIP(Contrastive Language-Image Pre-training)对于模型选择,作者团队也尝试了多种的尝试,发现CLIP的效果跟模型规模是有正相关的最终得到的效果是,CLIP在30多个数据集上基本都能与精心设计的模型打成平手甚至胜利,并且会有更好的泛化性使用CLIP的好处有很多,其中之一就是CLIP不需要再对数据进行标注,只需要获得文本—图像对就可以,像在社交平台上获得的图片跟他发布时的TAG就是一个很好的途径,这种数据往往比标注的数据更容易获取,另外,通过文本—图像对的这种数据集训练,使得其拥有了多模态的效果 在预训练过程中,作者团队采用了对比学习的方法,之所以使用这样的方法而不是用GPT就是因为语言的多样性导致对应关系有很多(例如一张图片可以从多个角度描述),所以我们只需要让图片与文本配对即可,通过这样就能达到很高的效率代码的实现在实现方面,通过论文所给伪代码# image_encoder - ResNet or Vision Transformer # text_encoder - CBOW or Text Transformer # I[n, h, w, c] - minibatch of aligned images # T[n, l] - minibatch of aligned texts # W_i[d_i, d_e] - learned proj of image to embed # W_t[d_t, d_e] - learned proj of text to embed # t - learned temperature parameter # 分别提取图像特征和文本特征 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] # 在得到特征时一般会尝试归一化 在归一化前,还涉及到了投射层,即np.dot(I_f, W_i),主要用来学习如何从单模态投射到多模态 # 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化 I_e = l2_normalize(np.dot(I_f, W_i), axis=1) T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 计算缩放的余弦相似度:[n, n] logits = np.dot(I_e, T_e.T) * np.exp(t) # 对称的对比学习损失:等价于N个类别的cross_entropy_loss labels = np.arange(n) # 对角线元素的labels loss_i = cross_entropy_loss(logits, labels, axis=0) loss_t = cross_entropy_loss(logits, labels, axis=1) loss = (loss_i + loss_t)/2步骤解释提取图像特征和文本特征:使用预训练的 image_encoder 和 text_encoder 分别提取图像 I 和文本 T 的特征,得到形状为 [n, d_i] 和 [n, d_t] 的特征向量。线性投射和归一化:对两个特征进行线性投射,分别用矩阵 W_i 和 W_t,得到相同维度的特征向量 I_e 和 T_e。对投射后的特征进行 l2 归一化,保证它们具有单位长度。计算缩放的余弦相似度:通过计算余弦相似度矩阵,得到形状为 [n, n] 的 logits 矩阵。这一步涉及将图像特征和文本特征进行相似度计算,并使用温度参数 t 进行缩放。对称的对比学习损失:创建标签 labels,其中包含了元素从 0 到 n-1。计算两个方向上的交叉熵损失:loss_i 是以图像为查询,文本为正样本的损失;loss_t 是以文本为查询,图像为正样本的损失。最终的损失是两个方向上损失的平均值,即 (loss_i + loss_t) / 2。这个损失函数的设计旨在通过最大化正样本之间的相似度、最小化负样本之间的相似度,来学习图像和文本之间的语义对应关系。这种对称性的设计可以帮助提升模型的泛化能力,使得图像和文本之间的表示更加一致和可靠。