标签搜索
.png)

搜索到
4
篇与
的结果
-
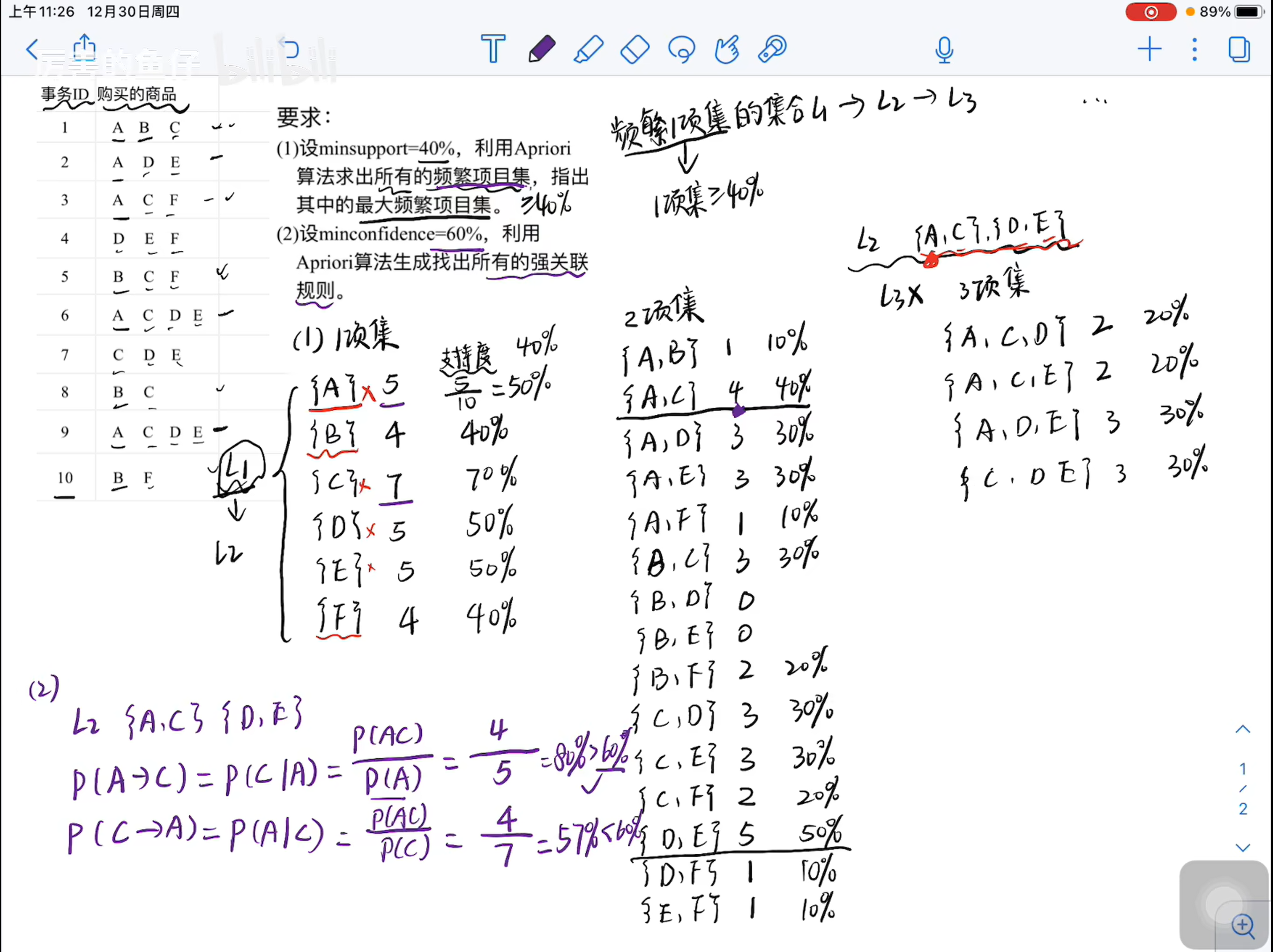
 数据挖掘 大数据挖掘数据挖掘数据挖掘定义技术层面:数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又包含潜在有用的信息的过程。数据准备环节数据选择 质量分析 数据预处理数据仓库从多个数据源搜集的信息存放在一致的模式之下特征化对目标数据的一般特性和特征汇总聚类分析最大化类内相似度 最小化类间相似性数据准备大数据定义超出正常处理范围 由海量数据+复杂类型的数据 构成数据对象组成数据集的元素,每个数据对象均为一个实体数据对象由属性描述数据存在问题数据不完整存在噪声数据数据不一致数据冗余数据不平衡数据的正确性分析缺失值数据错误度量标准错误编码不一致处理缺失数据忽视较小缺失率 有缺失值的样本或属性人工补全缺失值重新采样领域知识自动补全缺失值固定值均值基于算法插补法均值插补回归插补极大似然估计噪声过滤回归法均值平滑法离群点分析处理噪声数据局部离群因子LOF计算数据量子集选择数据量太大减小时间复杂度数据聚合尺度变换数据更稳定调整类分布不平衡数据哈尔小波交换通过调整分辨率数据标准化最小最大标准化Z-score标准化大数据挖掘与分析邻近性相似性和相异性统称为邻近性数据矩阵存放数据对象相异性矩阵存放数据对象的相异性值二元属性邻近性数值数据距离闵可夫斯基距离h=1 2 正无穷维度诅咒基于距离的聚类在高纬度下无效在高维情况下 P(0,1)更有效逆文档频率IDF 或 Goodall度量基本思路:将基本词汇看做全部属性的集合 每个词频是属性的值余弦度量余弦相似度逆文档频率 阻尼系数累计距离矩阵(大概率)计算等图算法题目APRIORI基本的Apriori算法 Apriori算法的基本思路是采用层次搜索的迭代方法,由候选(k-1)-项集来寻找候选k-项集,并逐一判断产生的候选k-项集是否是频繁的。 设C k 是长度为k的候选项集的集合,L k 是长度为k的频繁项集的集合。为了简单,设最小支持度阈值min_sup为最小元组数,即采用最小支持度计数。输入:事务数据库D,最小支持度阈值min_sup。 输出:所有的频繁项集集合L。 方法:其过程描述如下:通过扫描D得到1-频繁项集L1; for (k=2;Lk-1!=Ф;k++) { Ck=由Lk-1通过连接运算产生的候选k-项集; for (事务数据库D中的事务t) { 求Ck中包含在t中的所有候选k-项集的计数; Lk={c | c∈Ck and c.sup_count≥min_sup}; //求Ck中满足min_sup的候选k-项集 } } return L=∪kLk;这是通过Apriori计算最大频繁项集 和 计算强关联规则的题目要求为超过最小支持度 最小支持度的计算很简单即为Apriori优化基于散列的Apriori基于散列的Apriori技术基于Apriori算法, 为了解决此算法在数据集较大的情况下候选项集数量爆炸的问题 以及支持度计数效率低下的问题基于散列的优化:在生成候选项集时,通过哈希函数映射分桶 每个桶记录频数 如果桶中的频数小于最小支持度的阈值 则该桶中所有项集可以直接剪枝因为通过哈希函数可以快速找到相应的桶,所以计算效率较高h(x,y)=(hash(x)+hash(y))modn哈希树分组算法题目FPgrowth条件模式基的寻找在FPtree的项目里倒着找,沿着虚线将出现的频次进行统计,,写出条件模式基条件FP Tree沿着条件模式基画FP Tree 记得剪去最小支持度不够的项频繁项集将条件FPtree与项进行组合 得到频繁项集列式计数Apriori算法使用垂直数据格式挖掘频繁项集关联模式挖掘超集包含了另一个集合中所有元素的集合为超集闭模式一个频繁项集 没有任何它的超集具有与他相同的支持度也就是不被冗余覆盖的核心模式闭模式显著减少了需要存储的频繁模式数量可以推导出所有频繁模式及其支持度极大模式没有频繁的超集极大模式只保留频繁模式中“最大”的部分无法还原所有频繁模式的支持度信息序列模式序列模式是指诸如此类的模式,其项中包含多个项,在计数时,相同项仅计数一次聚类好的聚类方法产生高质量的聚类结果要求高类内相似性 高内聚低类间相似性 低耦合能够发掘隐藏模式 有价值聚类的好坏在于:相似度测量方法不同尺度 不同类型的距离函数设计不同主要聚类方法基于代表点的聚类代表性方法:kmeans kmedians kmedoids CLARANS层次方法基于准则对数数据层次分解代表性方法:Diana Agnes BIRCH CAMELEON基于密度的方法代表性方法:DBSACN OPTICS DENClue基于网格的方法代表方法:STING WaveCluster CLIQUE基于模型的方法代表性方法:EM SOM COBWEB聚类评估方法(概率低)熵不考哈熵 :可以反馈特征子集的聚类质量经验法肘方法交叉验证基于代表点聚类K meanskmedians选取代表点选取中值 对异常点不那么敏感Kmedoids从非代表点中随机选取点代替中心点集合中的某个点,重新划分 诸葛尝试 选择最优PAM1不受离群点数据影响2适于处理小数据集CLARA(小概率)基于抽样的方法 找到最优中心点集为目标CLAEANS(小概率)采样并随机选择层次聚类AGNES凝聚法不断将簇进行合并 最后得到所有合并后的集合为止DIANA法分裂法BirchCHAMELEON基于密度聚类发现任意形状簇Discover clusters of arbitrary shape能容忍噪音Handle noise一边扫描One scan需要以密度相关的参数作为终止条件DBSCAN原理: 对象的密度可以用靠近该对象的节点数量表示。 找出核心对象和其邻域,形成稠密区为簇参数:Eps : 邻域半径MinPts : 邻域半径内的最小节点数 判断是否为核心节点的阈值核心节点q 满足|N_Eps (q) | ≥ MinPts核心节点扩展区域 边缘节点定义边界或者OPTICS(可能不考)定义了两种距离,核心距离与可达距离对于不同对象可能有不同的可达距离DENCLUE(大概率不考)引入影响函数与密度函数的概念进行聚类离群点检测离群点Outlier:以一种不同机制产生的不同于大多数据表现的不正常的数据。如:虚假行为,电信诈骗,医药分析,网络攻击,等。与噪音数据区别噪音数据是错的数据是一个测量变量中的随机错误或误差 包括错误的值 偏离期望的孤立点噪音数据在数据处理前已经被移除。分类全局离群点情境(条件)离群点今天的最高温度是-15度集体离群点数据对象的子集形成集体离群点例如:一些计算机之间频繁发送信息离群点特征有趣的 少量的基于离群点方法检测出的离群点不能对应真正的异常行为只能为用户提供可疑数据基于密度的方法直方图通过直方图找到核密度估计确定数据中的稀疏区域以便报告异常点基于概率的方法极值:对应概率分布的统计尾部识别模型低概率区域中的对象一元离群点检测根据概率密度函数进行基于距离的方法基本思路数据集中显著偏离其他对象的点根据每个点在局部区域上的密度和其邻近点的密度来判断异常程度基于聚类的方法检测方法建立正常模型离群点为不能正常符合这个模型的数据点将异常数据度量为数值分数越大越可能是离群点形式基于聚类产生簇寻找远离簇的数据点考虑对象和它最近簇之间的距离半监督学习结合聚类与分类检测离群点先基于聚类识别正常簇,然后使用这个簇的一类模型识别离群点
数据挖掘 大数据挖掘数据挖掘数据挖掘定义技术层面:数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又包含潜在有用的信息的过程。数据准备环节数据选择 质量分析 数据预处理数据仓库从多个数据源搜集的信息存放在一致的模式之下特征化对目标数据的一般特性和特征汇总聚类分析最大化类内相似度 最小化类间相似性数据准备大数据定义超出正常处理范围 由海量数据+复杂类型的数据 构成数据对象组成数据集的元素,每个数据对象均为一个实体数据对象由属性描述数据存在问题数据不完整存在噪声数据数据不一致数据冗余数据不平衡数据的正确性分析缺失值数据错误度量标准错误编码不一致处理缺失数据忽视较小缺失率 有缺失值的样本或属性人工补全缺失值重新采样领域知识自动补全缺失值固定值均值基于算法插补法均值插补回归插补极大似然估计噪声过滤回归法均值平滑法离群点分析处理噪声数据局部离群因子LOF计算数据量子集选择数据量太大减小时间复杂度数据聚合尺度变换数据更稳定调整类分布不平衡数据哈尔小波交换通过调整分辨率数据标准化最小最大标准化Z-score标准化大数据挖掘与分析邻近性相似性和相异性统称为邻近性数据矩阵存放数据对象相异性矩阵存放数据对象的相异性值二元属性邻近性数值数据距离闵可夫斯基距离h=1 2 正无穷维度诅咒基于距离的聚类在高纬度下无效在高维情况下 P(0,1)更有效逆文档频率IDF 或 Goodall度量基本思路:将基本词汇看做全部属性的集合 每个词频是属性的值余弦度量余弦相似度逆文档频率 阻尼系数累计距离矩阵(大概率)计算等图算法题目APRIORI基本的Apriori算法 Apriori算法的基本思路是采用层次搜索的迭代方法,由候选(k-1)-项集来寻找候选k-项集,并逐一判断产生的候选k-项集是否是频繁的。 设C k 是长度为k的候选项集的集合,L k 是长度为k的频繁项集的集合。为了简单,设最小支持度阈值min_sup为最小元组数,即采用最小支持度计数。输入:事务数据库D,最小支持度阈值min_sup。 输出:所有的频繁项集集合L。 方法:其过程描述如下:通过扫描D得到1-频繁项集L1; for (k=2;Lk-1!=Ф;k++) { Ck=由Lk-1通过连接运算产生的候选k-项集; for (事务数据库D中的事务t) { 求Ck中包含在t中的所有候选k-项集的计数; Lk={c | c∈Ck and c.sup_count≥min_sup}; //求Ck中满足min_sup的候选k-项集 } } return L=∪kLk;这是通过Apriori计算最大频繁项集 和 计算强关联规则的题目要求为超过最小支持度 最小支持度的计算很简单即为Apriori优化基于散列的Apriori基于散列的Apriori技术基于Apriori算法, 为了解决此算法在数据集较大的情况下候选项集数量爆炸的问题 以及支持度计数效率低下的问题基于散列的优化:在生成候选项集时,通过哈希函数映射分桶 每个桶记录频数 如果桶中的频数小于最小支持度的阈值 则该桶中所有项集可以直接剪枝因为通过哈希函数可以快速找到相应的桶,所以计算效率较高h(x,y)=(hash(x)+hash(y))modn哈希树分组算法题目FPgrowth条件模式基的寻找在FPtree的项目里倒着找,沿着虚线将出现的频次进行统计,,写出条件模式基条件FP Tree沿着条件模式基画FP Tree 记得剪去最小支持度不够的项频繁项集将条件FPtree与项进行组合 得到频繁项集列式计数Apriori算法使用垂直数据格式挖掘频繁项集关联模式挖掘超集包含了另一个集合中所有元素的集合为超集闭模式一个频繁项集 没有任何它的超集具有与他相同的支持度也就是不被冗余覆盖的核心模式闭模式显著减少了需要存储的频繁模式数量可以推导出所有频繁模式及其支持度极大模式没有频繁的超集极大模式只保留频繁模式中“最大”的部分无法还原所有频繁模式的支持度信息序列模式序列模式是指诸如此类的模式,其项中包含多个项,在计数时,相同项仅计数一次聚类好的聚类方法产生高质量的聚类结果要求高类内相似性 高内聚低类间相似性 低耦合能够发掘隐藏模式 有价值聚类的好坏在于:相似度测量方法不同尺度 不同类型的距离函数设计不同主要聚类方法基于代表点的聚类代表性方法:kmeans kmedians kmedoids CLARANS层次方法基于准则对数数据层次分解代表性方法:Diana Agnes BIRCH CAMELEON基于密度的方法代表性方法:DBSACN OPTICS DENClue基于网格的方法代表方法:STING WaveCluster CLIQUE基于模型的方法代表性方法:EM SOM COBWEB聚类评估方法(概率低)熵不考哈熵 :可以反馈特征子集的聚类质量经验法肘方法交叉验证基于代表点聚类K meanskmedians选取代表点选取中值 对异常点不那么敏感Kmedoids从非代表点中随机选取点代替中心点集合中的某个点,重新划分 诸葛尝试 选择最优PAM1不受离群点数据影响2适于处理小数据集CLARA(小概率)基于抽样的方法 找到最优中心点集为目标CLAEANS(小概率)采样并随机选择层次聚类AGNES凝聚法不断将簇进行合并 最后得到所有合并后的集合为止DIANA法分裂法BirchCHAMELEON基于密度聚类发现任意形状簇Discover clusters of arbitrary shape能容忍噪音Handle noise一边扫描One scan需要以密度相关的参数作为终止条件DBSCAN原理: 对象的密度可以用靠近该对象的节点数量表示。 找出核心对象和其邻域,形成稠密区为簇参数:Eps : 邻域半径MinPts : 邻域半径内的最小节点数 判断是否为核心节点的阈值核心节点q 满足|N_Eps (q) | ≥ MinPts核心节点扩展区域 边缘节点定义边界或者OPTICS(可能不考)定义了两种距离,核心距离与可达距离对于不同对象可能有不同的可达距离DENCLUE(大概率不考)引入影响函数与密度函数的概念进行聚类离群点检测离群点Outlier:以一种不同机制产生的不同于大多数据表现的不正常的数据。如:虚假行为,电信诈骗,医药分析,网络攻击,等。与噪音数据区别噪音数据是错的数据是一个测量变量中的随机错误或误差 包括错误的值 偏离期望的孤立点噪音数据在数据处理前已经被移除。分类全局离群点情境(条件)离群点今天的最高温度是-15度集体离群点数据对象的子集形成集体离群点例如:一些计算机之间频繁发送信息离群点特征有趣的 少量的基于离群点方法检测出的离群点不能对应真正的异常行为只能为用户提供可疑数据基于密度的方法直方图通过直方图找到核密度估计确定数据中的稀疏区域以便报告异常点基于概率的方法极值:对应概率分布的统计尾部识别模型低概率区域中的对象一元离群点检测根据概率密度函数进行基于距离的方法基本思路数据集中显著偏离其他对象的点根据每个点在局部区域上的密度和其邻近点的密度来判断异常程度基于聚类的方法检测方法建立正常模型离群点为不能正常符合这个模型的数据点将异常数据度量为数值分数越大越可能是离群点形式基于聚类产生簇寻找远离簇的数据点考虑对象和它最近簇之间的距离半监督学习结合聚类与分类检测离群点先基于聚类识别正常簇,然后使用这个簇的一类模型识别离群点 -
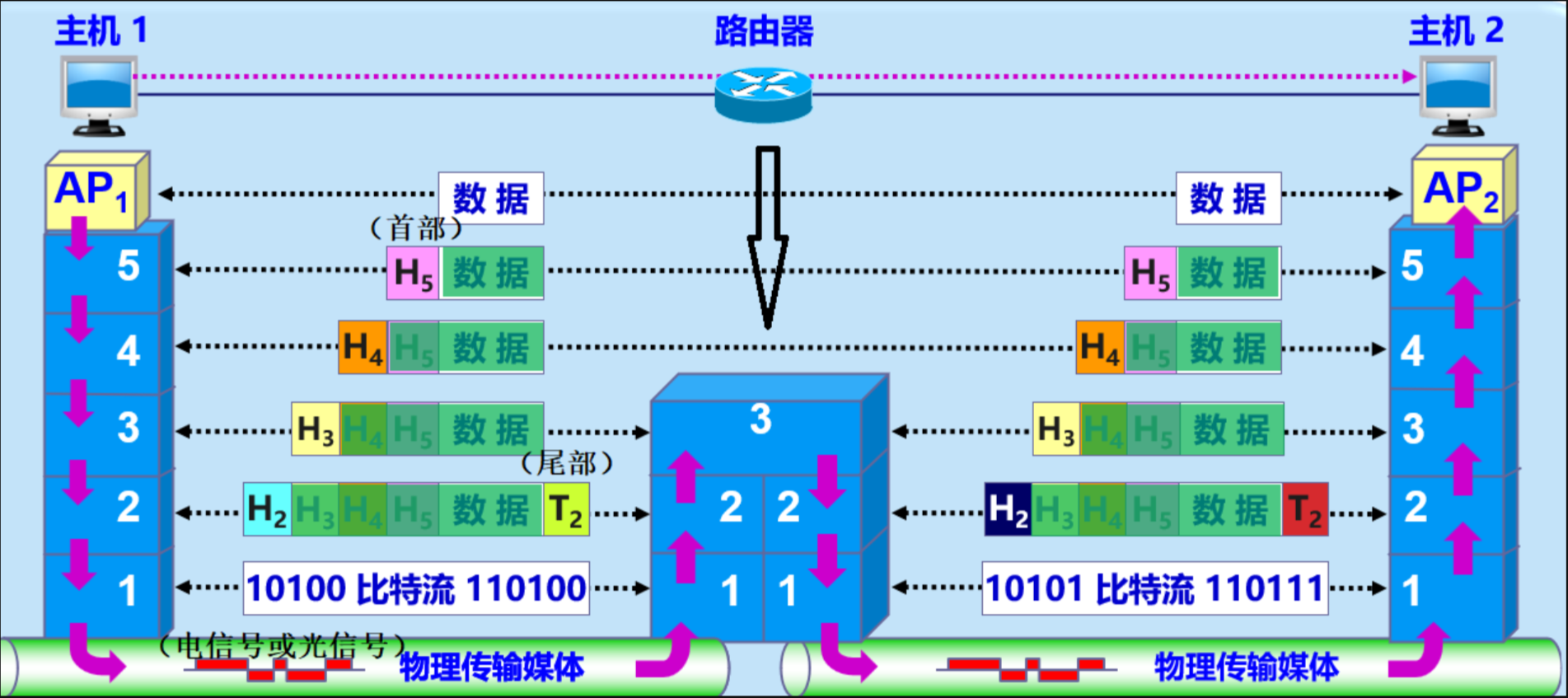
计算机网络期末复习 计算机网络计算机网络概念篇小碎点互联网服务提供者ISP ,可以是中国电信、中国移动、中国联通1Byte = 8 bit表示速率时 k = $10^3$表示数据量时 K = $2^{10}$数据量一般是KB 速率一般是kb/s总时延 = 发送时延+传播时延+处理时延+排队时延按照传输方向分类单工:只能单方向双工:在同一时间,线路上只能允许一个方向的数据通过全双工:双方可以同时进行数据通信OSI参考模型工作原理:应用层通过应用进程交互完成特定网络应用 交互的数据单元为报文运输层为两台主机中进程之间的通信提供数据传输服务 网络层为分组交换网上的不同主机提供通信服务 使用分组或数据报为数据单元数据链路层在相邻接点之间传送数据帧物理层实现比特传输物理层单位:bit 利用传输介质,网络结点之间建立数据链路层单位:帧 物理层基础上,提供节点到节点之间的服务,差错检测、流量控制网络层单位:分组 数据链路层基础上提供点到点之间的通信,提供路由功能,拥塞控制、网络互联传输层提供端到端之间的数据传输服务,实现对数据进行控制与操作的功能会话层负责维护通信中两个节点之间的会话建立维护和断开以及数据的交换表示层用于处理交互数据的表示方式,例如格式转换、数据加密与解密,数据压缩等功能应用层使用应用程序通过网络服务TCP/IP参考模型网络接口层物理层和数据链路层网际层网络层传输层传输层应用层会话层 表示层 应用层物理层四大特性机械特性 电气特性 功能特性 过程特性调制将任意信号转化为模拟信号编码将任意信号编码为数字信号传输介质双绞线屏蔽双绞线 STP抗干扰强、贵一些非屏蔽双绞线 UTP便宜、抗干扰差光纤单模光纤多模光纤(Multi Mode Fiber) - 芯较粗(50或62.5μm),可传多种模式的光。距离:2KM多模光纤单模光纤(Single Mode Fiber):中心纤芯很细(芯径一般为9或10μm),只能传一种模式的光。因此,其模间色散很小,适用于远程通讯,但还存在着材料色散和波导色散,这样单模光纤对光源的谱宽和稳定性有较高的要求,即谱宽要窄,稳定性要好。距离:100KM复用技术频分 时分 码分 波分传输方式基带传输:传输数字信号频带传输:传输模拟信号ICMP控制报文协议 是TCP/IP的子协议,用于在主机、路由器之间传递控制消息控制消息是指网络通不通,主机是否可达Ping的过程实际上就是ICMP协议工作的过程ARPIP地址解析成MAC地址虚电路面向连接进行数据传输,类似线路交换,但是并没有物理的电路建立虚拟电路后 沿着相同的VC传输 发收顺序完全相同 传输完毕后进行释放较适合站点之间大批量的数据传输冲突域冲突域就是所有节点竞争同一带宽 一般认为一个集线器就是一个冲突域交换机上一个连接就是一个冲突域
-
java期末速成 javajdk jre jvm.java-------->.class----jvm---->机器语言编写源文件 编译源文件生成字节码 加载运行字节码java语句执行顺序 顺序 选择 循环 异常处理基本语法方法格式权限修饰符 返回值声明 方法名称(参数列表){ 方法中封装的逻辑功能; return 返回值; }--权限修饰符--注释//单行注释 /* 多行注释 */ /** 文档注释 **/标识符举例java变量java是一个强类型语言 必须先声明类型后使用java数据类型分两大类 基本数据类型与引用类型引用数据类型:string 数组 接口 类按照声明位置进行定义分为局部变量与成员变量变量的类型转换boolean类型不参与转换自动类型转换容量小的类型自动转换成容量大的类型byte,short,int -> float -> long ->doublebyte short int之间不会互相转换 三者计算时会转化成int类型强制类型转换容量大的类型转换成容量小的类型时需要加上强制转换符变量的作用域在类体内定义的变量称为成员变量 作用域是整个类在一个方法或方法内代码块中定义的变量称为局部变量常量量前加一个final变量赋值注意事项:float a = 133f long a = 22220202l char c = '羊'数组数组初始化方式不允许在前面的[]里写元素个数动态两种int[][] arr = new int[3][]; arr[0] = new int[3] int [][] arr2 = new int[3][2] arr[0][0] = 33静态一种int arr4[][] = new int[][]{{1,2,3},{2,3,4}}arr.length 得到数组长度输入输出scanner类型#输入 Scanner s = new Scanner(System.in); s.nextInt(); s.nextLine(); s.nextfloat(); scanner.next(); #输出 System.out.println("XX");system.out. print() 普通输出 printf()格式化输出 println()换行输出类与对象封装继承多态我们进行一次举例public class Student { private String username; public String getUsername{ return username; } #这个函数存在而不使用直接赋值的意义就是因为username这个变量是私有的 public void setUsername(String username){ this.username = username; } } class Test { public static void main(String[] args) { Student student=new Student(); student.setUsername("张三"); student.getUsername(); System.out.println(); } }类的实例化通过new语句进行创建类的定义格式[修饰符] class 类名 [extends 父类名] [implements 接口名]{ //类体 包括类的成员变量与成员方法 }继承基类object没有选择继承的时候默认继承object,有很多自带方法继承格式public class Parent { private int age; public int getAge() { return age } public void setAge(int age) { this.age = age; } #有参 public Parent(int age){ this.age = age; } #无参 public Parent(){ } public void myprint(){ system.out.println("我是父类的myprint方法"); } } class Son extents Parent{ public static void main(String[]args) { Son son = new son(); son.age = 3; } }类的重写对相同的函数进行再次声明就可以进行重写类的封装将类的某些信息隐藏在内部,不允许直接访问而是提供get set方法public class Person { private intn age; private string name; public String getName(){ return name; } public int getAge(){ return age; } public void setName(String name){ this.name = name; } public void setAge(int age){ this.age = age; } }构造方法 重点构造方法定义主要用来创建对象时 初始化对象的 总与new一起使用在创建对象的运算符中 一个类可以有 多个构造函数 可根据参数个数不同或者参数类型不同区分 即构造函数的重载方法的重载重写重载重写区别this关键字在构造方法中指该构造器所创建的新对象也就是对应对象的属性也可以使用this关键字调出对象本身例如在一个对象的setAge中调用getAge注意:this只能在类的非静态方法中使用 静态方法与静态的代码块中不能出现this 原因 static方法在类加载时就已经存在了 但是对象在创建时才在内存中生成super关键字super关键字主要存在于子类方法中用于子类调用父类的方法例如子类重写了父类的一个方法 但是又想重新调用一次父类的方法就使用super关键字static关键字静态 的关键字静态变量静态方法静态代码块使用了static后的方法变成类方法 不需要new就能直接调用final关键字final修饰的类不能被继承final修饰的方法不能被重写 但是可以直接用final修饰的基本类型变量不可变 但是引用类型变量引用不可改变 但是引用对象的内容可以改变抽象类在class前加一个abstract来修饰抽象方法要在子类里进行实现 不然不正确接口将class替换为interface即可接口里所有定义的方法实际上都是抽象的public abstract变量只能为public static final类型的public abstract void add(); 等效于 void add();抽象类与接口的区别接口要被子类实现 抽象类要被子类继承接口中变量全为公共静态常量 抽象类中可有普通变量接口中全为方法的声明 抽象类中可以有方法的实现接口中不可以有构造函数 抽象类中可以有构造函数接口可多实现 而抽象类必须被单继承接口中方法全为抽象方法 而抽象类中可以有非抽象方法内存机制栈存放局部变量 不可以被多个线程共享系统自动分配空间连续 速度快堆存放对象 可以被多个线程共享每个对象都有锁空间不连续 速度慢 灵活方法区存放类的信息:代码 静态变量 字符串 常量等可以被多个线程共享空间不连续 速度慢 灵活垃圾回收机制程序员不能调用垃圾回收器 但是可以通过system.gc()建议回收未引用的会被回收finallize方法 每个对象都有这个方法 用来释放对象区域资源 一般不去调用递归算法递归头 什么时候不调用自己递归体 什么时候调用自己异常机制:try catch finally catch的顺序 先小后大声明抛出异常:throws手动抛出异常:throw自定义异常: 首先继承Exception 或者它的子类容器:Collection接口: List -》ArrayList LinkedList Vector Set-》HashSet 内部使用HashMap实现Map接口: 采用 key value存储数据 HashMap线程不安全 效率高 HashTable线程安全 效率低Iterator接口:遍历容器中元素泛型:Collections: 包含排序查找的工具类字符串比较中 == 与 equal的区别==:比较的是两个字符串内存地址(堆内存)的数值是否相等,属于数值比较;equals():比较的是两个字符串的内容,属于内容比较。多态多态体现为一个事物的多种形态 例如 父类引用变量可以指向子类对象isinstanceof 向上转型 将子类对象赋值给父类变量 向下转型 将父类对象赋值给子类变量注解也叫元数据 用于描述数据的数据基本注解:@Override 重写 在重写的方法前加入即可@SuppressWarnings 压制警告 在警告内容前加入 可以让我们暂时忽略特定的警告自定义注解[public] @interface 注解名 { 数据类型 成员变量名()[default 初始值] }注解跟类一样 会被编译为 注解名.class的字节码文件成员变量名后面的()必不可少反射机制一段程序在运行过程中 接受一个对象作为形参 该对象的编译时类型与运行时类型不一致 但是程序又需要调用该对象运行时的类中的方法这就需要引用反射机制 保证在程序运行过程中可以知道任意对象的运行时类型可以构造任意类的对象可以调用任意对象的属性和方法其实就是在运行时获取对象的属性与方法,例如对象.getClass内部类将一个类作为成员放在另一个类或者方法的内部嵌套类内部类可以分为 非静态内部类和静态内部类非静态内部类 是指 在非静态类的方法内访问某个变量时 先找局部变量 再找内部类的属性 最后找外部类的属性如果局部变量 内部类属性 外部类三者名字相同静态内部类是用static修饰的内部类都称为静态内部类静态内部类是一个普通类 可以包含静态成员 也可以包含非静态成员静态内部类不能访问外部类的实例成员 只能访问外部类的类成员lambda表达式当接口中只有一个抽象方法 匿名内部类的语法过于频繁这种接口叫做函数式接口表达式 : (形参列表)->{代码块}形参列表:如果形参列表中只有一个参数 形参列表的圆括号也可以忽略异常处理基本语法try{ 执行语句 }catch (ExceptionType e) { 异常处理 }finally{ 无论是否发生异常都会执行的语句 }创建Exception通过继承Exception来创建异常public class CustomException extends Exception{ public CustomException(String message){ super(message) } }throw/throws用于手动抛出异常 需要使用public void processAge(int age) { if (age < 0) { throw new IllegalArgumentException("Age cannot be negative"); } // 其他处理逻辑 }throwspublic String readFile(String fileName) throws IOException { // 读取文件内容的逻辑 }输入输出操作InputStreamInputStream是用于从各种源(如文件、网络连接等)读取字节流的抽象类。它定义了一系列用于读取字节的方法。你可以使用InputStream来读取二进制数据,比如图片、音频或视频文件。OutputStream是用于向各种目标(如文件、网络连接等)写入字节流的抽象类。它定义了一系列用于写入字节的方法。你可以使用OutputStream来写入二进制数据,比如将数据写入文件或通过网络发送。Reader是用于从各种源(如文件、网络连接等)读取字符流的抽象类。它定义了一系列用于读取字符的方法。你可以使用Reader来读取文本数据,比如读取文本文件中的内容。Writer是用于向各种目标(如文件、网络连接等)写入字符流的抽象类。它定义了一系列用于写入字符的方法。你可以使用Writer来写入文本数据,比如将数据写入文本文件。// 使用FileReader读取文件 FileReader fileReader = new FileReader("file.txt"); int data = fileReader.read(); // 读取一个字符 while (data != -1) { System.out.print((char)data); data = fileReader.read(); } fileReader.close(); // 使用FileWriter写入文件 FileWriter fileWriter = new FileWriter("file.txt"); fileWriter.write("Hello, world!"); fileWriter.close();System.in、System.out 和 System.errSystem.in、System.out和System.err是Java中的三个标准I/O流。System.in:标准输入流,通常对应于键盘输入。你可以使用它来从控制台读取用户的输入。System.out:标准输出流,通常对应于控制台输出。你可以使用它向控制台输出信息。System.err:标准错误流,也通常对应于控制台输出。与System.out不同的是,它主要用于输出错误信息。泛型java 中泛型标记符:E - Element (在集合中使用,因为集合中存放的是元素)T - Type(Java 类)K - Key(键)V - Value(值)N - Number(数值类型)? - 表示不确定的 java 类型Collection \<E>Collection 是 Java 集合框架中所有集合类的根接口。它代表了一组对象,这些对象通常称为元素。Collection 接口的主要特点包括:存储一组对象:Collection 是一个容器,可以存储多个对象,这些对象可以是任何类型,包括基本类型的封装类、自定义对象等。无序性:Collection 不保证元素的顺序,即它们不一定按照插入的顺序进行存储和访问。允许重复元素:Collection 允许存储重复的元素,即相同的对象可以被添加多次。常见实现类:Java 中常见的 Collection 实现类包括 List、Set 和 Queue 接口的各种实现类,如 ArrayList、LinkedList、HashSet 等。Map<K,V>Map 接口代表了一种映射关系,它将键映射到值。Map 中的键是唯一的,而值则可以重复。Map 接口的主要特点包括:键值对存储:Map 存储的是键值对,每个键都映射到一个值。通过键可以快速查找对应的值。键的唯一性:Map 中的键是唯一的,每个键最多只能与一个值关联。值的重复性:Map 中的值可以重复,即不同的键可以映射到相同的值。常见实现类:Java 中常见的 Map 实现类包括 HashMap、TreeMap、LinkedHashMap 等。
-
数据结构 树树的前中后序遍历前序遍历 根左右 每次左右可以展开时进行替换中序遍历 左根右后序遍历 左右根前中后序转化前中后序转化看遍历方式决定的顺序结构例如前序遍历的第一个元素一定是根节点 中序遍历的根节点的两边就是左右子树树与二叉树的转化树要变成二叉树,那就将树中的所有兄弟结点进行链接,然后每一层与上一层的连接只留下第一个结点的连接二叉树要变成树,那就反方向来一次,将除了第一个结点的其他结点与根节点连接上,然后将兄弟结点连接,这时候二叉树就变回了原来的树森林与二叉树的转化森林转化为二叉树,森林是由若干个树组成的,可以理解为森林中的每棵树都是兄弟,我们先把森林中的每棵树转化成二叉树,然后将从第二个树起的每个结点作为上一个结点的右孩子二叉树想转化成森林,先要看他可不可以转化,直接看根节点有没有右孩子,有就可以转化,先递归的将每个拥有右节点的根节点都断开 然后将二叉树再转化成树就成了森林树与森林的遍历树的遍历树的遍历很简单,分为先根遍历与后根遍历森林的遍历森林的遍历也分为两种,分别是前序遍历与后序遍历,森林的前序遍历与二叉树的中序遍历相同,森林的后序遍历与二叉树的中序遍历相同图图的表示邻接矩阵typedef struct { Vertextype vexs[MAXVEX]; EdgeType arc[MAXVEX][MAXVEX]; int numNodes, numEdges; }MGraph;邻接表int EdgeType; typedef struct { int adjvex; EdgeType info; struct EdgeNode *next; }EdgeNode; typedef struct { VertexType data; EdgeNode *firstedge; }VertexNode,AdjList[MAXVEX]; typedef struct { Adjlist adjList; int numNodes,numEdges; }AdjList;深度优先搜索深度优先搜索也叫DFS,这种搜索如其名,深度优先,在走之前先确定一个方向,比如先访问最左边的,那就持续往前走,在未遇到过的结点的路中选择最左边的即可//邻接矩阵 #define MAXVEX 9 Boolean visited[MAXVEX] void DFS(MGraph G,int i) { int j; visited[i] = True; printf("%c",G.vexs[i]) for(j = 0;j < MAXVEX;j++) { if(G.arc[i][j] == 1 && visited[i] == False) { DFS(G,j); } } } void DFSTraverse(MGraph G) { int i; for(i = 0;i < G.numvertexes;i++) { visited[i] = False; } for(i = 0;i < G.numvertexes;i++) { if(!visited(i)) { DFS(G,i); } } }//邻接表 void DFS(GraphAdjList GL,int i) { EdgeNode *p; visited[i] = True; printf("%c",GL->adjlist[i].data); p = GL->adjlist[i].firstedge; while(p) { if(!visted[p->adjvex]) { DFS(GL,p->adjvex); } p = p->next; } } void DFSTraverse(GraphAdjlist GL) { int i; for(i = 0;i < GL->numvexes;i++) { visited[i] = False; } for(i = 0;i < GL->numvexes;i++) { if(!visited[i]) { DFS(GL,i); } } }广度优先搜索广度优先搜索,也叫BFS核心思想是一层一层访问结点,使用的是一个栈来作为辅助存储,从入栈第一个节点开始,每次出栈一个结点,就将这个结点邻接的所有未访问顶点入栈,由此来遍历所有顶点void BFSTraverse(MGraph G) { int i; Queue Q; for(i = 0;i < G->numvexes;i++) { visited[i] = False; } InitQueue(Q); for(i = 0;i < G->numvexes;i++) { if(!visited[i]) { visited[i] = True; printf("%c",G->vex[i]) EnQueue(&Q,i); while(!EmptyQueue(Q)) { DeQueue(&Q,&i); for(j = 0;j < G->numvexes;j++) { if(G.arc[i][j]&&!visited[j]) { printf("%c",G->vex[j]); EnQueue(&Q,j); } } } } } }最小生成树prim算法简介prim算法的核心就是迭代,从一个顶点开始构建生成树,每次讲代价最小的新顶点纳入生成树,直到所有顶点都纳入为止。实现思想创建两个数组,一个是标记是否加入的数组isjoin,一个是计算各节点加入最小生成树的最低代价的数组lowcost 在此之前先选取第一个结点,对此结点的相邻边进行遍历,将有权边加入到lowcost中供选择 第一轮循环遍历各个结点,找出lowcost最低的并且未加入树的顶点,将相邻结点加入isjoin数组中并开启下一轮遍历,更新还未加入的各个顶点的lowcost值不断循环直至所有顶点都纳入为止因为要进行n-1轮的循环,每次循环2n次总时间复杂度是O($n^2$)即O($|V|^2$)kruskal算法简介kruskal算法的核心就是全局里去找,每次选择一条权值最小的边,使这条边的两头连通(若原本已经连通则不选)直到所有顶点都连通实现思想初始时先将各条边按照权值进行排序然后使用并查集方法检查是否已连通,若未连通则将新节点加入,一共要执行e轮,美伦判断两结点是否属于同一集合,需要O($log_2e$)最短路径BFS求无权图的单源最短路径简介直接进行广度优先遍历使用两个数组,一个记录最短路径值,一个记录到这个顶点的直接前驱只能用无权图迪杰斯特拉算法简介dijkstra算法是一种一步一步找出最短路径的方法,核心思路就是从初始点开始,一步一步从已确定路径中选取最短的路径作为新的最短路径,并加入新已确定顶点,然后执行多次实现我们选用三个数组,分别是标记各顶点是否已找到最短路径的finals,最短路径长度的dist,以及记录路径上的前驱的path也就是我们每次将可到达的结点找出来,从可获取路径中找到最短路径,并将其前驱记录,标记出结点时间复杂度为O($n^2$)即O($|V|^2$)如果用于负权值带权图,则迪杰斯特拉算法可能会失效弗洛伊德算法简介Floyd算法是求出每一对顶点之间的最短路径使用动态规划思想,将问题的求解分为多个阶段对于个顶点的图G,求任意一对顶点Vi一>Vj之间的最短路径可分为如下几个阶段:初始:不允许在其他顶点中转,最短路径是?0:若允许在Vo中转,最短路径是?1:若允许在Vo、V1中转,最短路径是?2:若允许在Vo、V1、V2中转,最短路径是?......n-1:若允许在Vo、V1、V2.Vn-1中转,最短路径是?例如这样,左边的矩阵就是初始时,不中转获得的个顶点建最短路径长度,右边的矩阵是初始时中转点的记录,因为不中转,所以是-1若允许在V0中转,则新加一编辑 如此经历n轮递推woc,大道至简,本身以为是只有一个节点做中转的情况,但是仔细一想,它并不是单源的算法,而是点到点的算法,并且也从来不是每次加一个这么简单,他是考虑了所有的结点 就好比是需要经过 0 2 4 6才能到这个点,在查找时0->2是最小值不需要中转,0->4是经过2的中转,0到6是经过4的中转,但是到4的中转前已经中转过2了,所以这种算法已经考虑了所有的情况DAG简介有向无环图简称DAG 图DAG描述表达式相同部分可以合并节省存储空间顶点中不能出现重复的操作数,标出来各个运算符的生效顺序,注意分层拓扑排序简介拓扑排序就是找到做事的先后顺序每个AOV网可能有一个或者多个拓扑排序实现①从AOV网中选择一个没有前驱(入度为0)的顶点并输出。②从网中删除该顶点和所有以它为起点的有向边。③重复①和②直到当前的AOV网为空或当前网中不存在无前驱的顶点为止。使用三个数组进行实现分别是 记录当前顶点入度的数组indegree 记录拓扑序列的数组print 保存度为零的顶点栈s逆拓扑排序将拓扑排序中的入度更换成出度即可,使用邻接表不适合实现逆拓扑排序,应该使用逆邻接表或者邻接矩阵查找查找的衡量方法为平均查找长度顺序查找基本思想是从线性表的一端开始,逐个检查关键字是否满足给定的条件。若查找到某个元素的关键字满足给定条件,则查找成功,返回该元素在线性表中的位置。若查找到表的另一端,仍未找到符合给定条件的元素,则返回查找失败的信息。折半查找基本思想就是二分法散列表基本概念散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这些情况为冲突,这些发生碰撞的不同关键字称为同义词。散列表建立了关键字和存储地址之间的一种直接映射关系。散列函数不同,散列表不同直接定址法就是直接使用线性函数确定地址,一般不常见除留余数法确定一个数m,所有的数对设定的数m进行取余,取余后进行散列表的排序解决冲突办法如果有重复则将其使用向后推移并记录查找次数的方法进行储存,成为开放定址法,也可使用链表进行存储,称为拉链法查找长度散列表的查找长度取决于三个因素:散列函数、处理冲突的方法和装填因子。装填因子a=表中记录数n/散列表长度m。散列表的平均查找长度依赖于散列表的装填因子α,不直接依赖于n或m。α越大,表示装填的记录越“满”,发生冲突的可能性就越大。排序插入排序直接排序实际上就是进行比较后一步步替换空间复杂度为O(1)时间复杂度为O($n^2$)-->两个嵌套for循环(平均)稳定性 稳定 (遇到相同数字,相对位置保持不变)每次向后移动一次即一趟排序希尔排序希尔排序是通过一个常数d作为增量,然后对于相隔d个增量的记录作为子表进行排序,经过几次排序,使得整个表格基本有序后,对全体进行一次排序即可因为同样使用常数个辅助单元,所以空间复杂度为o(1)时间复杂度依赖于增量d,一般来说是不确定的,所以一般我们不去考虑最后两个相同数字的相对位置也不能保证,所以稳定性也是不稳定的交换排序冒泡排序不做解释,一一交换空间 O(1)时间O($n^2$)快速排序快速排序是选取一个固定数,通常为第一个数,将小于这个数的跟不小于这个数的值进行排序,然后依次进行,是一个递归的过程所以空间复杂度是O($log_2n$)时1间复杂度是O($nlog_2n$)稳定性为不稳定快速排序是所有内部排序算法中平均性能最优的算法但是并不适用于本身就已经有了一定顺序的序列进行排序选择排序简单选择排序就是遍历每个元素,在遍历到第i个元素时,选择从i到n的所有元素中最小的一个,将其与第i个元素进行交换空间复杂度为O(1)时间复杂度为O($n^2$)稳定性为不稳定堆排序对于二叉树的排序结果,我们可以根据根节点存放的是最大结点还是最小结点将堆分为大根堆与小根堆对于大根堆小根堆的构造,都是从$n/2$开始进行的对于堆的删除操作,就是将栈顶元素输出后再次进行构造对于堆的插入操作,我们将其放入栈尾,再次进行构造空间复杂度O(1)时间复杂度O($nlog_2n$)稳定性 不稳定归并排序归并排序是将两个或两个以上的有序表组成一个新的有序表例如二路归并排序,就是将元素两两组合并进行排序空间复杂度是O(n)时间复杂度是O($nlog_2n$)稳定性 为稳定基数排序不基于比较与移动进行排序,而是基于关键字各位的大小进行排序空间效率 O(r)时间复杂度O(d(n+r))稳定性 稳定各种排序算法的比较插帽龟跟统计鸡是很稳定的插帽龟在选冒插的时候,恩慌了恩老说快归堆问题树的度为树中最大的度,例如二叉树的度为2树中的指针域,看图理解即可含有n个结点的树含有n+1个空链域,n-1个非空链域,可以从画图理解,从第一个结点为2个空域,每增加一个结点,空域增加一个前后缀表达式前缀表达式首先先看,前缀表达式是从后往前算,遇到数字一个个放入栈中,遇到符号则拿出栈顶的元素进行计算,后进先算后缀表达式先入先出,从前往后进行计算,也就是通过队列进行实现二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树。二叉搜索树:一棵二叉树,可以为空;如果不为空,满足以下性质:非空左子树的所有键值小于其根结点的键值。非空右子树的所有键值大于其根结点的键值。左、右子树都是二叉搜索树。二叉链表用二叉链表存储哈夫曼树,有m个叶子结点,问哈夫曼树中总共多少个空指针域:2m,叶子节点数*2数据的物理存储结构主要包括链式存储与顺序存储二叉排序树插入新节点时间复杂度为O(n),因为最差情况为单链以链表为栈的存储结构出栈时以链表为栈的存储结构出栈时必须判空,不需要判定满栈顺序线性表插入脑残数据的最小单位是数据项归并排序落单丢掉substr(str,int,int)意思是str的第int开始的int个字符层次遍历初始堆无法保证得到一个有序的序列,因为堆的兄弟结点之间无序创建邻接表的时间复杂度无向图中有n个结点e条边,建立该图邻接表的平均时间复杂度为O(n+e)深度为k的完全二叉树中最少有$2^{k-1}$个结点如上一趟排序结束后不一定能选出一个元素在其最终位置上的排序算法希尔排序,可能没有元素在最终位置上连通图是无向图连通图一定是无向图,所以深度优先遍历连通图一定能够访问到所有的顶点链式栈的栈顶元素删除删除栈顶元素操作序列 top = top->next初始化堆筛选法建初始堆必须从第$\frac{n}{2}$个元素开始进行筛选,因为第$\frac{n}{2}$个元素都有孩子结点(对于所有的完全二叉树来讲都是这样)新建元素x = (类型)malloc(sizeof(元素))